Die Vorteile von asynchronen Prozessen in REST-Anwendungen mit Java Spring nutzen
In einem früheren Artikel haben wir besprochen, wie wichtig es für das Softwareentwicklungsteam ist, die Geschäftslogik einer Softwarelösung/eines Softwareprodukts sowie die angestrebten Funktionen und Features zu verstehen. Die wichtigsten Ergebnisse sind ein starker Fokus auf das, was aus geschäftlicher Sicht am wichtigsten ist, weniger Nacharbeit und saubere Release-Pläne.
Aber das Verstehen der Ziele einer Softwarelösung/eines Softwareprodukts kann auch einige der kleineren Details beeinflussen – zum Beispiel, was passiert, wenn der Benutzer auf eine Schaltfläche oder einen Link klickt. Im einfachsten Fall wird die gewünschte Aktion ausgeführt, und das Ergebnis wird sofort erreicht/angezeigt (d. h., es folgt ein synchroner Prozess). In anderen Fällen muss der Benutzer möglicherweise auf ein Ergebnis warten, während Teile der Oberfläche vorübergehend unzugänglich/deaktiviert sind (d. h. während eines asynchronen Prozesses).
Die Wait-/No-Wait-Fälle werden vom Product Owner entschieden und vom Softwareentwicklungsteam als sich gegenseitig ausschließende synchrone/asynchrone Prozesse implementiert:
- Bei synchronen Prozessen kann der Benutzer auf das Ergebnis warten und es sich dann anzeigen lassen. Einmal gestartet (z. B. durch einen Klick), kann der Prozess nicht mehr unterbrochen werden.
- Asynchrone Prozesse können entweder vom Benutzer oder von einem automatisierten Scheduler als „fire and forget“ gestartet werden: Die Aktion wird gestartet, aber man wartet (oder kümmert sich) nicht darum, dass sie ausgeführt wird und das Ergebnis angezeigt wird. Manchmal wird eine Startmeldung angezeigt, und der Status kann während der Ausführung überprüft werden.
Asynchrone Prozesse können auf viele verschiedene Arten verwendet/implementiert werden. Wir schauen uns fünf konkrete Situationen an:
- Versenden einer Benachrichtigungsmail am Ende eines Benutzervorgangs, an dem auch andere Benutzer beteiligt sind
- Hochladen mehrerer Dokumente mit Abbruchfunktion
- Ausführen einiger komplexer Berechnungen im Backend, die durch eine Benutzeraktion angefordert werden
- Ein paar automatisch geplante Systemaktionen durchführen lassen
- Importieren großer Datenmengen aus einem externen System in unsere Anwendung
1. Versenden einer Benachrichtigungsmail am Ende eines Benutzervorgangs, an dem auch andere Benutzer beteiligt sind
Einige der Benutzer werden Vorgänge durchführen, die auch andere Benutzer betreffen – zum Beispiel einen Kommentar zu einem Artikel hinterlassen, der von jemand anderem erstellt wurde. In diesem Fall wollen wir den Kommentar im Backend speichern und den Autor des Artikels über den neuen Kommentar informieren. Wenn der Benutzer auf „Kommentar speichern“ klickt, wird der einzelne Backend-Aufruf daher zwei Dinge tun: den eigentlichen Kommentar speichern und eine E-Mail an den Ersteller des Artikels senden.
Das Speichern des eigentlichen Kommentars wird sofort durchgeführt, da der anfragende Benutzer die Rückmeldung benötigt, dass er gespeichert wurde. Aber das Versenden der E-Mail ist nicht etwas, das den anfragenden Benutzer betrifft, also wird das Backend einen asynchronen Prozess auslösen, ohne auf das eigentliche Ergebnis zu warten. Das bedeutet eine schnellere Antwortzeit für die Benutzer und keine Belästigung mit Fehlermeldungen, wenn beim Versenden der E-Mail etwas schiefläuft.
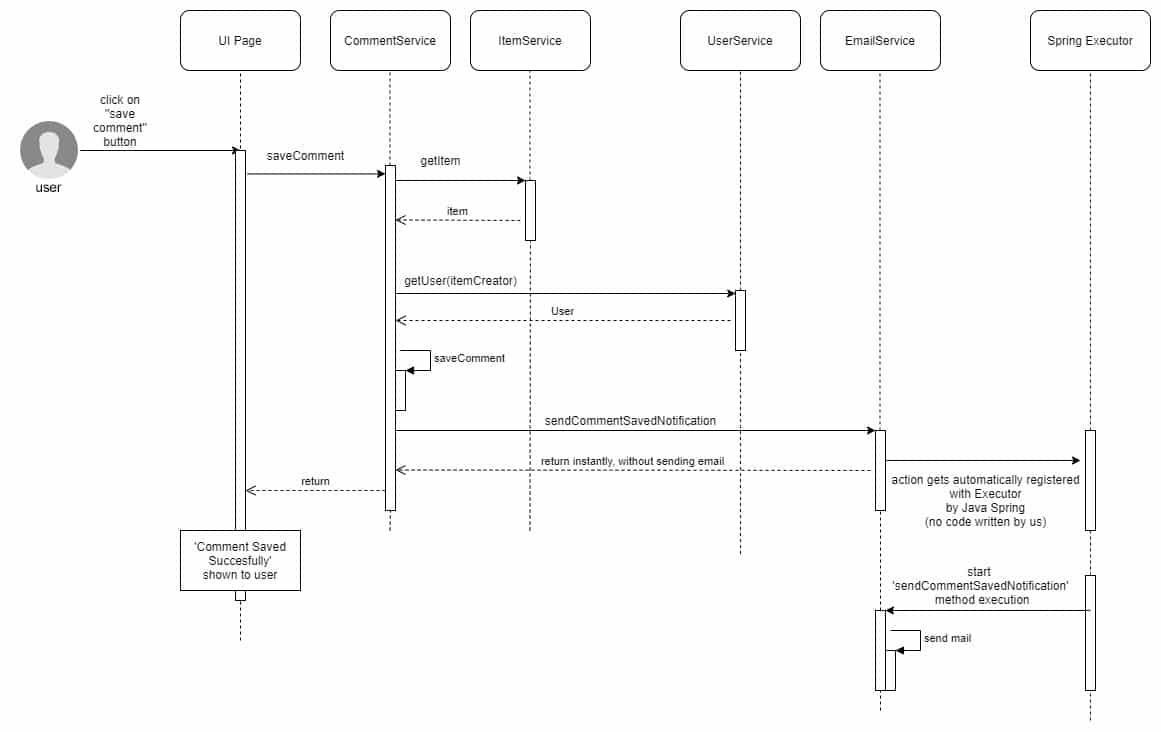
public class CommentService { public void saveComment(String id, CommentRequest comment) { Item item = itemService.getItem(id).orElseThrow(ItemNotFoundException::new); User userToNotify = userService.get(item.getCreator).orElseThrow(UserNotFoundException::new) commentService.save(comment); mailService.sendCommentSavedNotification(userToNotify, comment); } } public class EmailService { @Async public void sendCommentSavedNotification(User userToNotify, Item item) { MimeMessageHelper mimeMessage = //prepare your email content here javaMailSender.send(mimeMessage); } }
Sie können sehen, dass mailService.sendCommentSavedNotification(…) wie ein normaler Methodenaufruf aussieht. Aber aufgrund der @Async-Annotation auf der eigentlichen Methodenimplementierung greift Spring ein und tut etwas im Hintergrund: Es verwendet einen ThreadExecutor, um einen neuen Thread zu erzeugen. (Die eigentliche Ausführung dieser Methode findet in diesem neuen Thread statt.) Daher wird der Befehl mailService.sendCommentSavedNotification sofort zurückgegeben. Der ThreadExecutor ist, wenn er nicht explizit in der Anwendung definiert ist, der Standard-ThreadExecutor von Spring (SimpleAsyncTaskExecutor), und das Einzige, was Sie tun müssen, ist, ihn in einer Konfigurationsdatei wie dieser zu aktivieren:
@Configuration @EnableAsync public class AsyncConfiguration implements AsyncConfigurer {//no special body needed yet}
2. Hochladen mehrerer Dokumente mit Abbruchfunktion
Ein weiterer Anwendungsfall ist das Hochladen mehrerer Dokumente auf einmal, um sie an einen Artikel anzuhängen. Die Dokumente befinden sich möglicherweise auf einem Server eines Drittanbieters, was bedeutet, dass das Hochladen einige Zeit in Anspruch nehmen kann. Während der Wartezeit kann der Benutzer einen Ladebalken sehen und den Vorgang abbrechen.
Wie das funktioniert?
Das Frontend sendet die Dokumente an das Backend und erhält eine Prozess-ID. Mit dieser Prozess-ID kann das Frontend das Hochladen des Dokuments jederzeit abbrechen (wenn der Benutzer auf die Schaltfläche Abbrechen klickt), indem es einen Abbruchaufruf durchführt und die Prozess-ID übergibt.
Dies ist nur möglich, weil das Hochladen von Dokumenten im Backend asynchron abläuft, und das Backend die Prozess-ID zurückgeben kann, bevor der Upload abgeschlossen ist. Damit der Dokumenten-Upload-Prozess den Abbruch unterstützt, muss er aktiv auf Abbruchaktionen prüfen und er muss wissen, wann er beendet ist.
Wir erhalten also einen komplexeren Prozess, der gestartet, beendet oder abgebrochen werden kann. Alle diese Prozessstadien werden in einer Ereignistabelle gehalten, die sowohl vom Frontend als auch vom Backend verwendet wird, um den Fortschritt zu verfolgen und dem Benutzer ein Ergebnis anzuzeigen, wenn der Prozess (erfolgreich oder mit Fehlern) beendet ist.
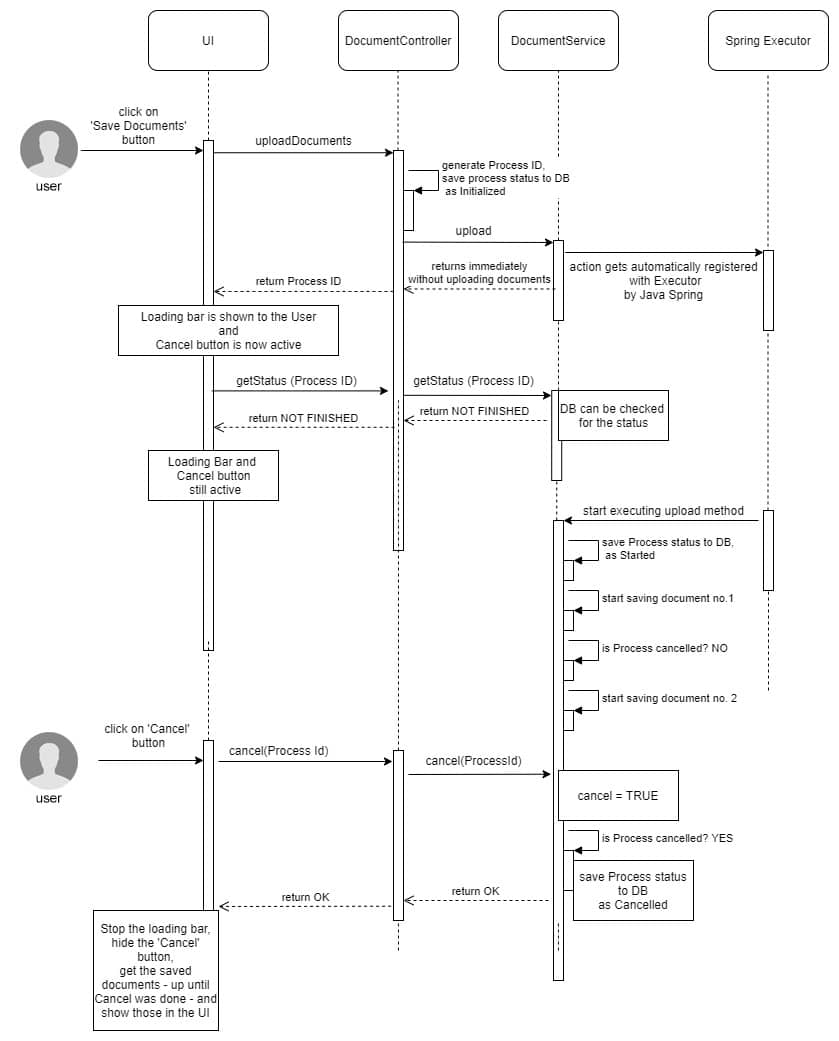
public class DocumentController { @PostMapping("/files")//start multiple upload, return processId right away public ResponseEntity<ProcessIdResult> uploadDocuments(@Valid @NotNull @RequestPart("files") List<MultipartFile> files, @RequestParam("item") String itemId) { String processId = ULID.nextUlid();//generate random Id
documentService.upload(processId, itemId, files); //call async method
return new ResponseEntity<>(new ProcessIdResult(processId), HttpStatus.ACCEPTED); } @PostMapping("/cancel")//cancel a specific process ResponseEntity<ProcessIdResult> cancelUploadDocuments(@RequestParam("processId") String processId) {
documentService.cancel(processId); //send cancel event for this processId
return new ResponseEntity<>(HttpStatus.ACCEPTED); } @GetMapping("/status")//get the status of a specific process public ResponseEntity<ProcessIdStatus> getStatus(@RequestParam("processId") String processId) {
ProcessIdStatus status = documentService.getStatus(processId); //check status for this processId
return new ResponseEntity<>(status, HttpStatus.OK); } } public class DocumentService { Async//using default Spring thread executor public void upload(String processId, String itemId, List<MultipartFile> files) { //send start event for this processId //start actual upload, checking after each document upload if cancel event was received //send finish/cancel/failed event for this processId at the end } }
Wie Sie sehen können, haben wir
- eine asynchrone Methode,
- prozessbezogene Ereignisse, die den aktuellen Status des Prozesses wiedergeben,
- und eine ProzessID, die vom Frontend benötigt wird, um den Prozessstatus zu prüfen oder abzubrechen, verwendet.
3. Komplexe Berechnungen im Backend, die durch eine Benutzeraktion angefordert werden
Ein weiteres Nutzungsszenario: Der Benutzer möchte eine Aktion ausführen, aber das Backend muss prüfen, ob er autorisiert ist, bevor die Anfragen tatsächlich ausgeführt werden. Je nach Kontext ist die Autorisierung nicht einfach, und es können komplexe Berechnungen erforderlich sein. In unserem Beispiel unten muss die Autorisierung an mehreren Stellen / über mehrere Prozesse hinweg geprüft werden, wobei jeder Microprozess sein eigenes Autorisierungsergebnis liefert.
Konkreter: Ein Anwendungsbenutzer möchte einen Kommentar zu einem vorhandenen Element abgeben (siehe 1. oben). Abhängig von der Geschäftslogik könnten nur bestimmte Benutzer berechtigt sein, Kommentare zu posten. Um die Berechtigungen eines Benutzers zu prüfen, muss das Backend möglicherweise mehrere Aufrufe an verschiedene Microservices durchführen. Um dies zu beschleunigen, sollten alle diese Aufrufe parallel initiiert werden.
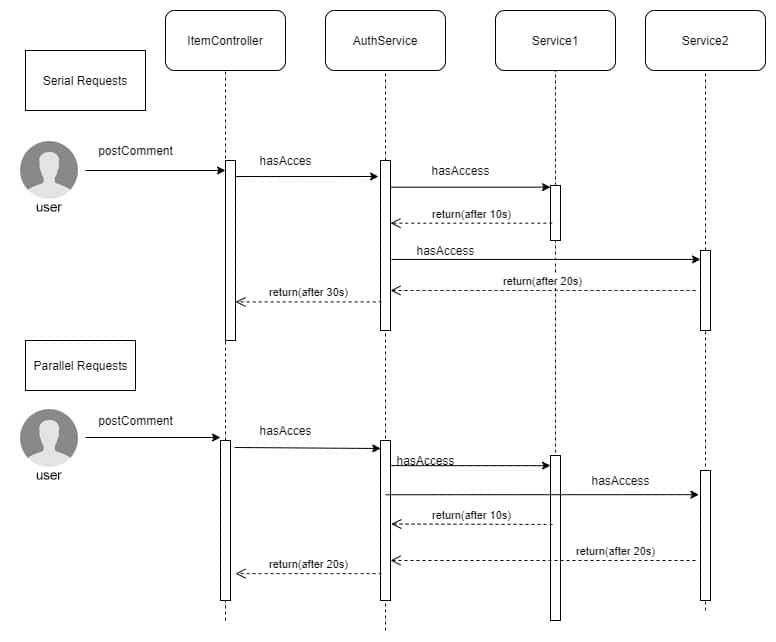
Hier kommt Javas CompletableFuture zur Hilfe:
public class AuthorizationService { public boolean hasAccess(User user, Item item) { List<CompletableFuture<Boolean>> parallelRequests = new ArrayList<>(); CompletableFuture<Boolean> hasRightsInService1Future = createFutureCallService1(user, item); CompletableFuture<Boolean> hasRightsInService1Future = createFutureCallService2(user, item); //run the http calls in parallel CompletableFuture<Void> combinedFuture = CompletableFuture.allOf(parallelRequests.toArray(new CompletableFuture[]{})); try { //wait until all are finished combinedFuture.get(); Boolean authorizedInService1 = hasRightsInService1Future.get();//get the actual response of the call Boolean authorizedInService2 = hasRightsInService2Future.get(); return authorizedInService1 && authorizedInService2; } catch (ExecutionException exception) { throw new CustomException(exception.getMessage); } } public CompletableFuture<Boolean> createFutureCallService1 (User user, Item item) { return CompletableFuture.supplyAsync(() -> callService1(user,item), futureExecutor); } public CompletableFuture<Boolean> createFutureCallService2 (User user, Item item) { return CompletableFuture.supplyAsync(() -> callService2(user,item), futureExecutor); } }
Auch hier sehen wir, dass ein Executor benötigt wird (siehe futureExecutor in der letzten Codezeile), um die Treads bereitzustellen, auf denen die einzelnen Aufrufe ausgeführt werden. Dies kann der Standard-Executor von Spring oder ein benutzerdefinierter Executor sein (wir werden weiter unten detailliert beschreiben, wie man ihn erstellt).
Da wir nun mehrere parallele Aufrufe haben, ist es wichtig zu beachten, dass jede Protokollierung innerhalb eines eigenen Threads erfolgen sollte. Zum Nachverfolgen von REST-Aufrufen verwenden wir Spring Sleuth, eine Ergänzung zum Anwendungslogger, die eine TraceID für jeden REST-Aufruf erstellt und an die Protokolle anhängt. Dies ist großartig für synchronisierte REST-Aufrufe, aber wenn es um asynchrone Aufrufe geht, müssen wir den ThreadExecutor anpassen, um eine TraceID für jeden Thread zu haben.
Das Einbinden von Sleuth in die Anwendung ist sehr einfach:
- Dazu fügen Sie einfach diese Zeile in build.graddle ein:
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
- Fügen Sie dann in logback-spring.xml diese Eigenschaft hinzu:
<property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%5p) %clr([${springAppName},%X{X-B3-TraceId:-},%X{X-B3-ParentSpanId:-},%X{X-B3-SpanId:-}]) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
@Configuration @EnableAsync public class AsyncConfiguration implements AsyncConfigurer { @Bean(name = "futureExecutor") public Executor getFutureExecutor() { ExecutorService executor = Executors.newFixedThreadPool(10);//added executor with 10 Threads return new LazyTraceExecutor(beanFactory, executor);//sleuth-specific: now each thread will have a traceId } }
4. Automatisch geplante Systemaktionen
Scheduler sind asynchrone Features, die von Spring automatisch zu einem bestimmten Zeitpunkt gestartet werden. Um das Scheduling in Spring zu aktivieren, müssen wir nur eine weitere Anmerkung in der AsyncConfig-Datei hinzufügen:
@Configuration @EnableAsync @EnableScheduling public class AsyncConfiguration implements AsyncConfigurer {// body here}
Anschließend müssen wir nur noch eine Methode in unserer CustomScheduler-Komponente erstellen, die diese Anmerkung enthält:
@Component public class CustomScheduler() { @Scheduled(cron=”0 0 0/2 * * ?”) public void runScheduledActions(){//scheduler operations here} }
Die Cron-Expression kann angepasst werden, indem sie in der application.yml oder an einer anderen Stelle hinzugefügt wird. (Wie man sie einstellt, ist leicht zu finden.) Je nach Bedarf können weitere Parameter zur @Scheduled-Annotation hinzugefügt werden. Außerdem kann der Methode runScheduledActions() eine @Async-Anmerkung hinzugefügt werden, um parallele Aufrufe zu unterstützen, sodass jeder Lauf in einem eigenen Thread ausgeführt wird.
5. Importieren großer Datenmengen aus einem externen System in unsere Anwendung
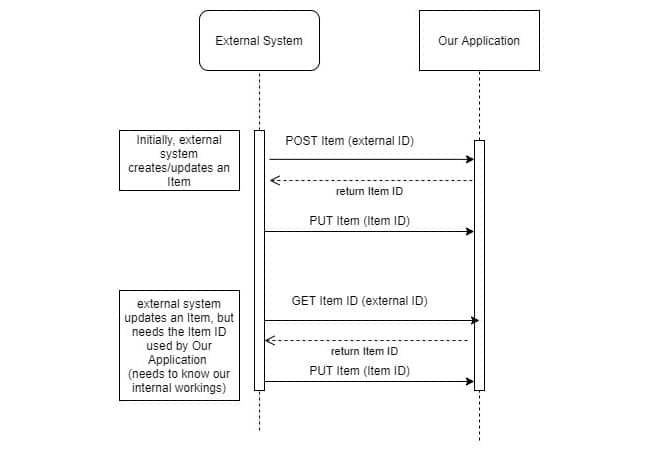
Manchmal werden die Artikelobjekte von einem externen System erstellt und in unsere Anwendung importiert. Der Import kann auf zwei Arten erfolgen:
eine geplante Aktion auf Seiten des externen Systems, die jeden Tag oder zu einem bestimmten Datum ausgeführt wird.
eine getriggerte Aktion, die jedes Mal ausgelöst wird, wenn ein neues Element im externen System erstellt wurde.
Bei einem getriggerten Import erhält unsere Anwendung Artikelaktualisierungen (fast) sofort. Der Nachteil: Wenn das externe System viele gleichzeitig aktive Benutzer hat, kann unsere Anwendung eine Menge Importaufrufe erhalten, da alle Elemente auf einmal erstellt werden. Dies führt zu einer Überlastung der Kommunikation zwischen den beiden Systemen, mit erhöhten Antwortzeiten für das externe System. Das externe System führt einen direkten synchronisierten Aufruf an unsere Anwendung durch, daher bedeutet jede Verzögerung von unserer Seite eine Verzögerung auf deren Seite.
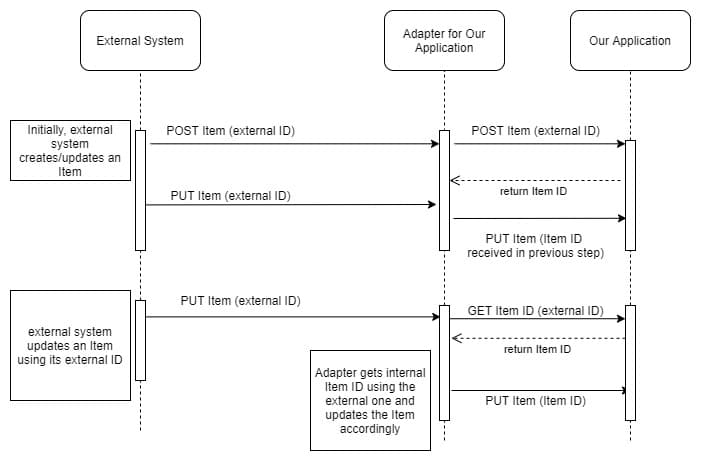
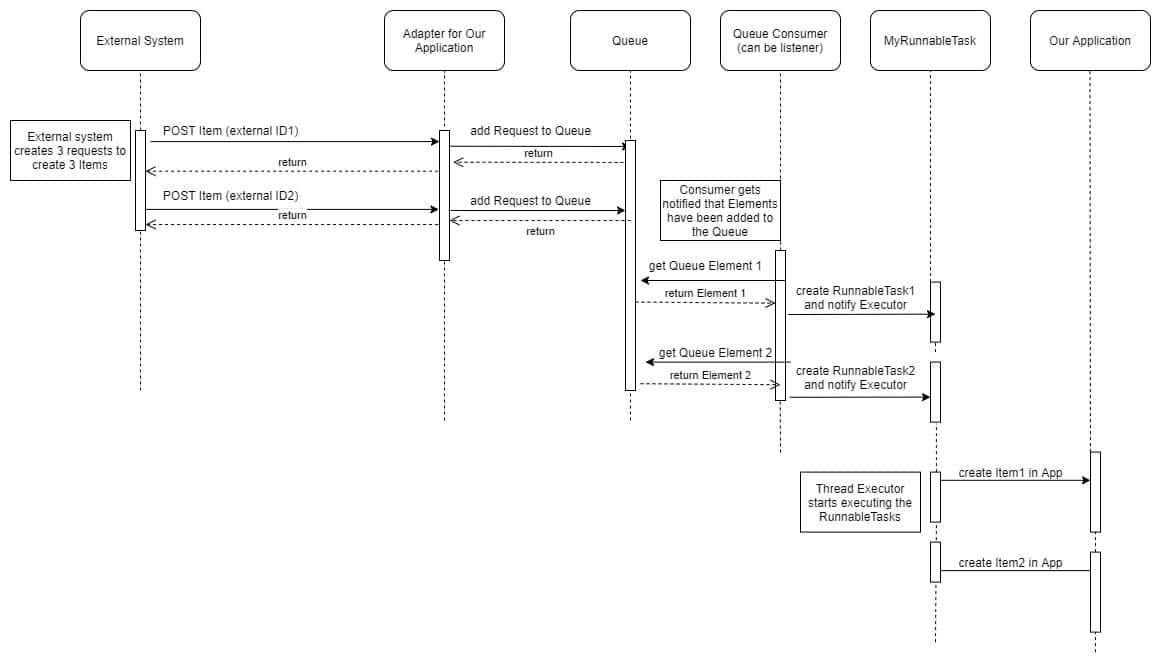
public void itemAdded(Item item) { MyRunnableTask jobQueueTask = new MyRunnableTask(item); jobQueueTask.run(); } public class MyRunnableTask () { private int runId; private List<String> usedLocks; @Async(“customJobExecutor”) public void runImportActions(){//import operations here} }
Bitte beachten Sie, dass wir für jede Listener-Benachrichtigung (itemAdded) eine neue runnable Aufgabe erstellen müssen, und diese wird diejenige sein, die asynchron läuft. Auf diese Weise können wir eine separate Task-Instanz für jeden Durchlauf haben, so dass alle internen Mitglieder (wie runID oder usedLocks) nicht zwischen den Durchläufen/Tasks geteilt werden.
Fazit
Async-Prozesse können auf viele Arten verwendet werden, wobei angepasste Executors in jeder einzelnen Situation helfen. Ein wichtiges Element der asynchronen Implementierung ist, ob das Ergebnis eine „wait for“ oder eine „fire and forget“-Aktion ist.
Besonderes Augenmerk muss auf parallele Ausführungen gelegt werden, vor allem wenn sie auf denselben Entitäten operieren. Java-Synchronisation kann helfen, aber man muss auch sicherstellen, dass die in den Berechnungen verwendeten Zwischenobjekte nicht zwischen den Läufen geteilt werden.
***
Und wie machen Sie das? Möchten Sie Ihre Lösung mit uns teilen?